Optimisation Algorithms for Hyperparameter Tuning
- Category: Machine Learning, Research
- Technologies: Python, Scikit-learn, Tensorflow, Pytorch, Deep-Neural-Networks Ray-Tune, Pandas, Matplotlib
- Skills: Academic Reading & Writing
- Repository: Github Link
- Report: Read Here
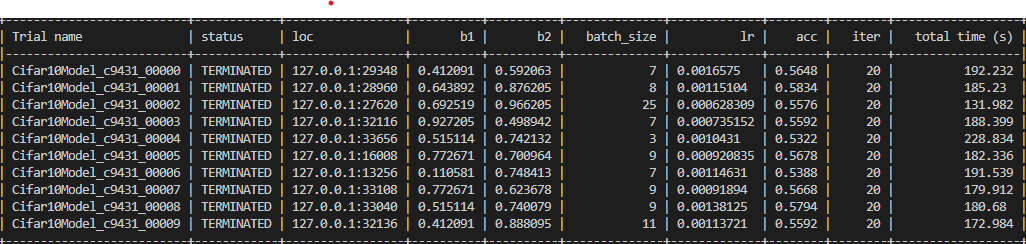
This paper investigates the performance of two gradient-free optimisation algorithms for Machine Learning hyperparameter selection. These hyperparameters are selected for a Convolutional-Neural-Network designed to classify on the CIFAR-10 Dataset. The following are the hyperparameters to be selected, SGD mini-batch size, Adam α, momentum variables β1, β2 and constant α.
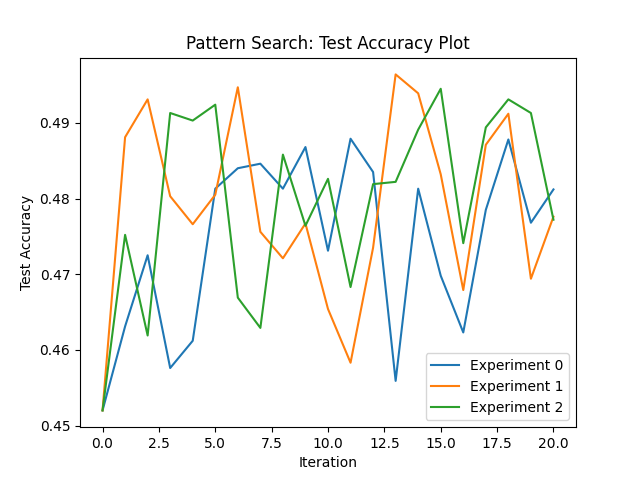
The first algorithm is Pattern Search which is a local search algorithm that mantains a grid of all hyperparameter permutations and explores the grid by evaluating permutations from region to region.
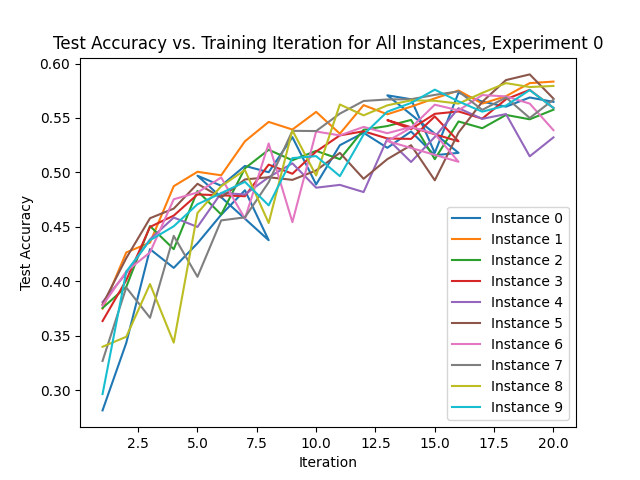
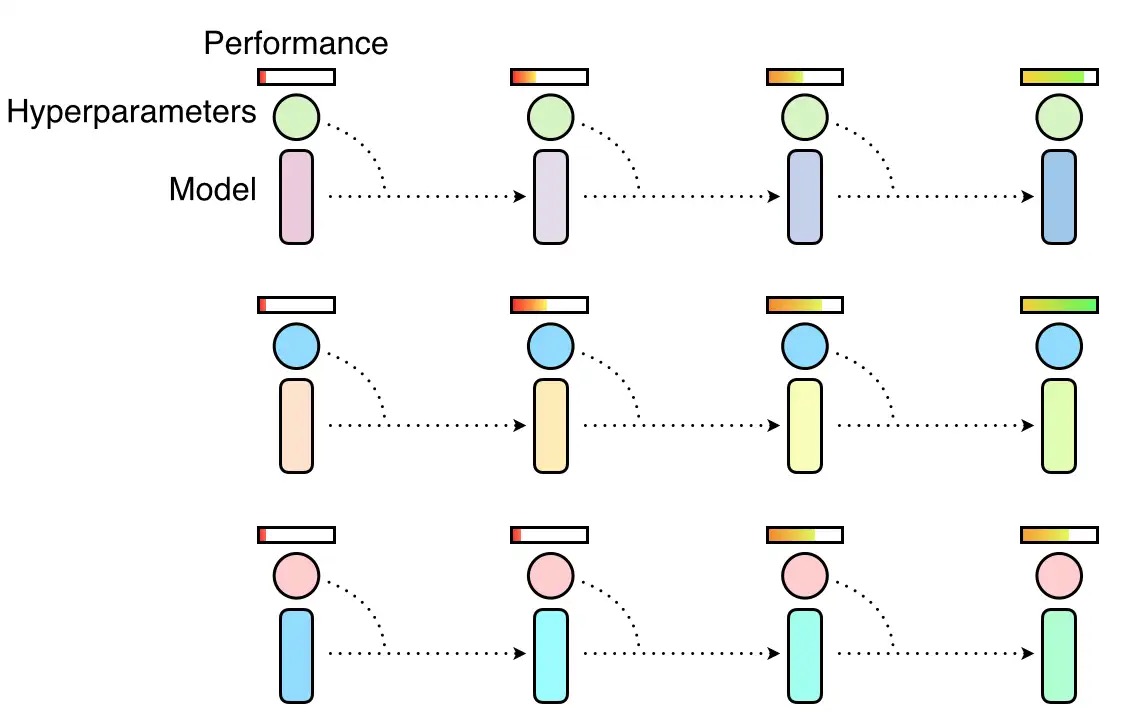
The second algorithm is Population Based Training which is a global search method proposed by Deep Mind and is a variant of Random Search. This algorithm simultaneously trains multiple instances of the neural network where, occasionally, some instances will copy the parameters of the best performing instances, perturb them slightly and continue to train.
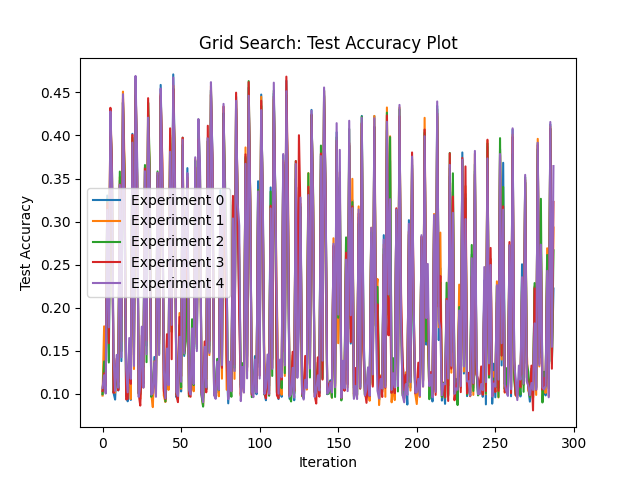
To evaluate the performance of these algorithms, Grid Search is used as a baseline comparison algorithm. Grid Search takes a brute-force approach and consecutively evaluates every permutation of hyperparameters and returns the one that produces the highest score. The output of Grid Search will inspire the range of hyperparameters to be used in Pattern Search and Population Based Training as well.
It is found that although each algorithm reaches similar accuracy scores on the CIFAR-10 dataset, Population-Based-Training proves to be the most efficient gradient free optimsation algorithm since it fine-tunes hyperparameters during training. Furthermore, Pattern Search and Population-Based-Training significantly outperfrom the brute-force approach of Grid Search.